ARCHITECTONIC STUDIES OF RADIO
Radio Explorations is an experimental research project that combines machine learning tools with design of data observatories: web-based interfaces that facilitate searching and navigating across the digital archive of radio signals. Machine learning algorithms, more specifically the self-organizing map (SOM)1, operate in this space as mechanisms of differentiation: a way of ordering differences based on probability. These unsupervised processes for organising unstructured data demonstrate working with data observatories as negentropic, synthesis-oriented ways to acquire knowledge about different types of transmissions.
Could we identify a signal based on its similarity to other, known signals? Which signals sound the most like bird songs? The project gives access to this incomplete archive in an organized way, presenting the radio enthusiast as well as a researchers interested in information studies, digital humanities or media materiality, with ways to navigate the signal space according interests and questions we might want to ask it.
In addition to exploring effective ways to organise digital data, the project problematizes what is sometimes referred to as ‘digital literacy’ 2, namely how computation and networks work and what we can learn with them. I engage in a practice of experimenting with machine learning algorithms in order to challenge instrumental categorizations of technical artefacts, such as radio signals. Inspired by the feminist critique of technoscience, I propose becoming skilled in using these advanced computational techniques differently, as one possible mode of resistance. The outputs of the Radio Explorations project gesture at a possible way for doing this.

radio signal observatory
KNOWING SIGNALS
What we know about radio signals spans different domains of human sensibility and legibility. For example, a communication engineer knows how the signals ‘sounds’ in its demodulated form, how its spectrogram looks like. More importantly, they know how the signal works, how information is modulated on the carrier wave, at which frequency it occurs and where. How can we move across these different domains of knowing signals, without acquiring the depth and span of expert knowledge, but having access to a large collection of signals as artifacts?
Currently, radio signals are categorized according to their frequency band (VLF, LF, MF, HF, VHF, UHF) or use in military, aviation, satellite, radar, marine, navigation, amateur domains. Two primary modalities, acoustic and visuals are typically used to access information on present and past radio transmissions. Different modes of demodulation and parameters for transforming signals into the visual domain (i.e Short-time Fourier transform, STFT) can give us the different perspectives on signal qualities necessary to understand or at least identify a signal.
In the study I present, the database of radio signals is reorganized according to the similarities and patterns identified in data on signals themselves and not their taxonomical distinctions. These similarities are encoded in terms of different features extracted in computational anaylsis of their audio samples: probability of silence, spectral entropy and audio fingerprints.
DATA OBSERVATORIES
Data observatories are part of the method and ambition to organise radio signal data according to properties that come from the dataset, for articulating the archive in its own terms. They give access to the knowledge of signals in their concrete manifestation: as they were received and recorded. We encode signals in terms of properties that are shared across the entire database. One of these properties is the probability of silence, another is the spectral entropy in the audio sample, a third is an audio identification technique called fingerprinting3. The SOM machine learning algorithm trains on each of these property sets, and produces an organized space - a codebook - that can be navigated and explored in three dimensions: according to proximity of codebook cells (horizontally and vertically) as well as according to the content of one cell (depth). By encoding the data in this way, the database gets an informational face, a different one for every property we analyze.
This work proceeds by developing web-based interfaces for navigating the space of radio signals database according to an observer’s interest. Which signals are grouped together in one cell, or close to each other? What is the most similar signal to ‘Bird oddity’? How is a signal distributed across the signal space? What properties are common to signals in nearby cells?
We produced two different views on the signal archive, two studies that use the same techniques of differentiation. The visual language for both studies is based on the SOM codebook vectors grid: chunks of radio signal audio samples are distributed across the cells of the map. Codebook, the first study, explores radio signal data alone, while the second study, Projections, explores projections of the radio signal data on an external dataset which is closer to human experience, such as music, bird songs, urban sounds.
about the dataset
STUDY 01: CODEBOOK
This study proposes nine algorithmically identified topics as a starting point in the exploration of the radio signals archive. The SOM algorithm is trained on short (1s or 5s) chunks of audio samples of all radio signals in the database (identified and non-identified), using their different representations – silence, noise, fingerprints. Even though we can observe some regions separate and some patterns emerge, it is not possible to make meaningful inferences from these arrangements alone. Radio signals are intended for machine-machine communication and only translated into information upon reception. We, however, work with recordings of radio transmissions, without examining their content. The resulting organisation needs to be approached through a different domain, which, in this case is the adjacent domain of textual descriptions, associated with each signal in the database. We used the Latent Dirichlet allocation (LDA) for topic modeling of descriptions and rely on its list of most important keywords to spark the interest in observations. There are words that speak of military use and international relations (spying and jamming); there are very technical words which speak of protocols and demodulation; there are groups of words that are associated with radio amateurs. Starting from one of these topics, the archive unfolds in directions of individual interests, tracing similarities across sometimes completely unrelated signals.

To explore the interface, please use the Descriptions link on the left.
STUDY 02: PROJECTIONS
The second study builds on the previously described techniques, and enables the comparison of radio signals by articulating their similarity in terms of an external dataset: the Free Music Archive (FMA)4. First, a SOM is trained on a generic music library with equal representation of eight musical genres. Then radio signal data is projected on this organisation and articulated in terms of songs. We could make a very rapid shortcut here, that radio is close to Instrumental music and Folk. The main interest is to explore this organisation deeper, which qualities and features of radio signals can we observe because of this organisation. This study enables observation of unexpected similarities across signals and regions, suggesting the possibility to identify signals of unknown origin by triangulating their similarity to music and radio signals in neighbouring cells.
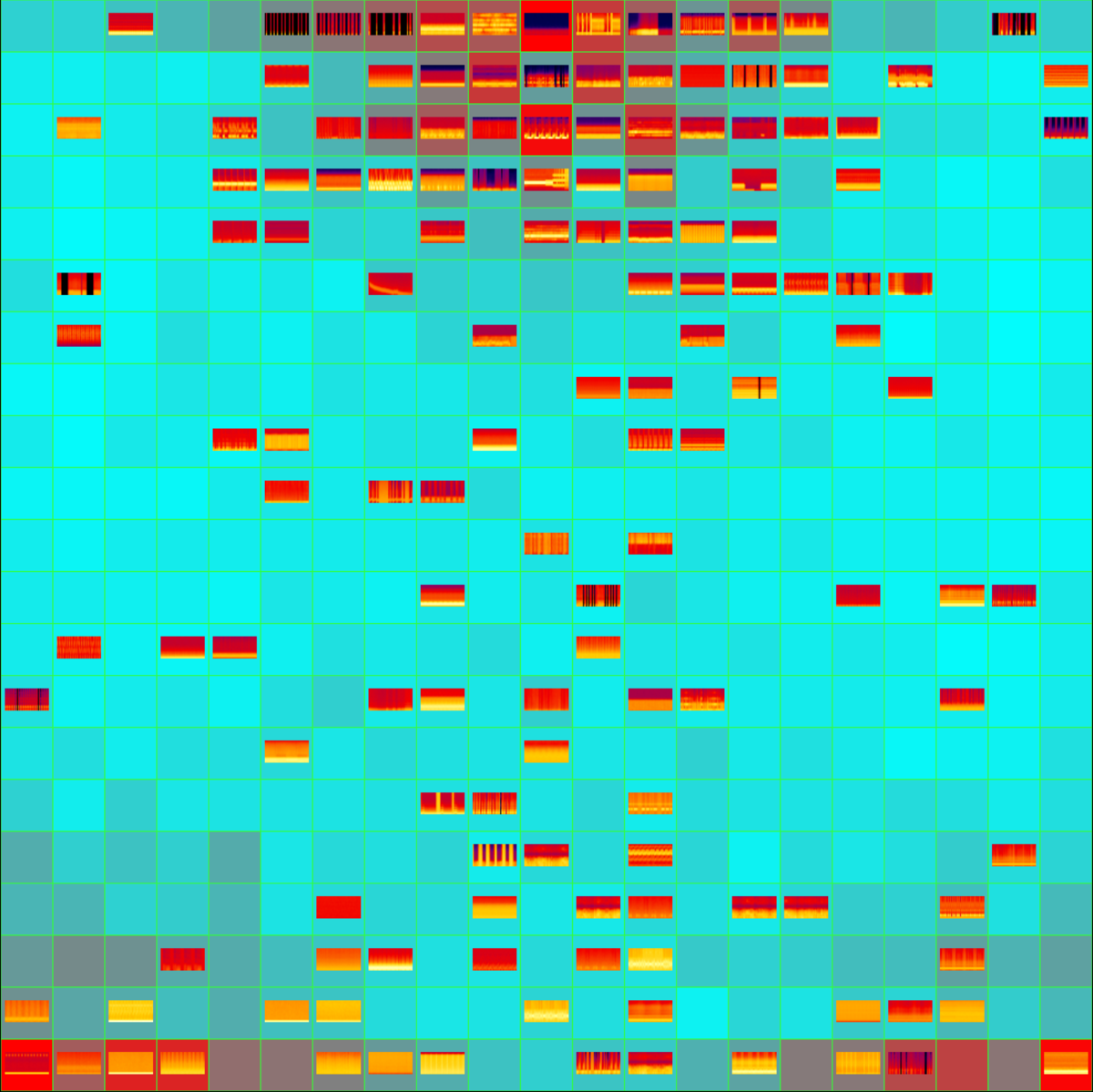
To explore the interface, please use the Projections link on the left.
PROJECT OUTLOOKS
Radio cannot be known through engineering knowledge alone, nor can it be reduced to any singular domain. Neural networks of the SOM algorithm extract whatever they determine as essential information from the data on radio signals, but they also do not give us any reason for it: reason itself stays in a kind of a black box. Working with SOM as instrument, and not looking for semantic relationships, we are able to recognize affinities and interests as the main driver of these explorations.
The outputs of this project aim to facilitate speculation on the connection between signal representation and technical communication protocols, by shifting criteria of similarity from taxonomical and instrumental (i.e used in military) or physical (i.e high or low frequency), to properties shared across all signals - such as the probability of silence or noise in the signal.
The other important idea demonstrated with this project is to see working with machine learning and code on a level which is not about problem solving, but about articulating: it is about techniques of organizing information to tell a story, rather than showing the objectivity of the world. Data observatories are computational setups that provide measurements of similarity between data points, and enable a multiplicity of perspectives on the data.
The dataset that I am working with is not just simply a database. It testifies of a knowledge community that forms around the question of technical literacy of telecommunications. One of the collateral outputs of this work is the use of digital observatories as tools to assist the identification process for signals that are currently categorized as unknown. This path will be explored in future work.
about the team
-
Kohonen, T. (1982). Self-organized formation of topologically correct feature maps. Biological Cybernetics, 43(1), 59–69. https://doi.org/10.1007/BF00337288 ↩︎
-
Colman, F., Bühlmann, V., O’Donnell, A., & van der Tuin, I. (2018). Ethics of Coding. A Report on the Algorithmic Condition. H2020-EU.2.1.1. – INDUSTRIAL LEADERSHIP – Leadership in enabling and industrial technologies – Information and Communication Technologies. http://cordis.europa.eu/project/rcn/207025_en.html; Vee, A. (2017). Coding literacy: how computer programming is changing writing. The MIT Press. ↩︎
-
Fingerprints are a condensed digital summary of an audio signal, based on peak points in the spectrogram which represent higher energy content. The technique is known for its use in Shazam music identification application. See: Wang, A. L.-C. (2003). An industrial-strength audio search algorithm. Proceedings of the 4 Th International Conference on Music Information Retrieval. https://doi.org/10.1.1.217.8882 ↩︎